How to build Lakehouse Architecture on AWS (Part 3)
Following part 1, the following section will introduce a reference architecture that uses AWS services to create each layer described in the Lakehouse architecture. Part 2 went into depth about the Ingestion Layer and Storage Layer, part 3 will clarify the remaining two important layers, completing the overview of the Lakehouse Reference Architecture.
See also part 1 on the How to build Lakehouse Architecture on AWS (Part 1) – Viet-AWS (awsviet.vn)
See also part 2 on the How to build Lakehouse Architecture on AWS (Part 2) – Viet-AWS (awsviet.vn)
3. Data Processing Layer
The processing layer of the Lakehouse Architecture provides a variety of purpose-built components that enable a wide variety of data processing and use cases, in a single structure (flat, hierarchical, or unstructured tabular) architecture) and the speed (batch or streaming) of the dataset in Lakehouse. Each component can read and write data to both Amazon S3 and Amazon Redshift (collectively, storage of Lakehouse architecture).
We can use process layer components to build data processing jobs that can read and write data stored in both data warehouse and data lake storage using the following interfaces:
- Amazon Redshift SQL (with Redshift Spectrum)
- Apache Spark jobs running Amazon EMR.
- Apache Spark jobs running on AWS Glue
You can add metadata from the resulting datasets to a central Lake Formation catalog using the AWS Glue data collector or the Lake Formation API.
You can use purpose-built components to build data transformation pipelines:
- SQL-based ELT using Amazon Redshift (with Redshift Spectrum)
- Big data processing using AWS Glue or Amazon EMR
- Near-real-time streaming data processing using Amazon Kinesis
- Near-real-time streaming data processing using Spark Streaming on AWS Glue
- Near-real-time streaming data processing using Spark Streaming on Amazon EMR
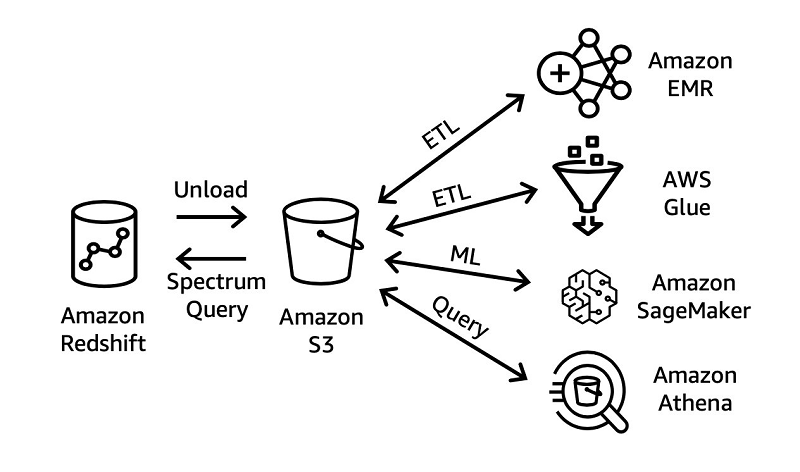
3.1. SQL based ELT
To transform structured data in the Lakehouse storage layer, you can build powerful ELT pipelines using familiar SQL semantics. These ELT pipelines can use batch parallel processing (MPP) in Amazon Redshift and the ability in Redshift Spectrum to create thousands of temporary nodes to scale processing to petabytes of data. Similar stored procedure-based ELT pipelines on Amazon Redshift can transform the following:
- Flat structured data delivered directly to Amazon Redshift staging tables by AWS DMS or Amazon AppFlow
- Data is stored in data lake using open source file formats such as JSON, Avro, Parquet and ORC
For data enrichment steps, these pipelines may include SQL statements that join internal dimension tables to large fact tables stored in data lake S3 (using the Redshift Spectrum class). As a final step, data processing pipelines can insert curated, enriched, and modeled data into Amazon Redshift internal tables or external tables stored in Amazon S3.
3.2. Big data processing
For integrated processing of large volumes of semi-structured, unstructured, or highly structured data stored on the Lakehouse storage layer (Amazon S3 and Amazon Redshift), you can build big data jobs using Apache Spark and run them on AWS Glue or Amazon EMR. These jobs can use open source connectors as well as Spark native to access and combine relational data stored in Amazon Redshift with complex flat or hierarchical structured data stored in Amazon S3. These same jobs can store processed data sets back to the S3 data lake, Amazon Redshift data warehouse, or both in the Lakehouse storage layer.
AWS Glue provides serverless, pay-per-use, per-use ETL to enable ETL pipelines to handle tens of terabytes of data, without the need to manage servers or clusters. To speed ETL development, AWS Glue automatically generates ETL code and provides commonly used data structures and ETL transformation (to validate, clean, transform, and flatten data). AWS Glue provides built-in capabilities for processing data stored in Amazon Redshift as well as the S3 data lake.
In the same workflow, AWS Glue can load and process Amazon Redshift data stored in flat table format as well as datasets stored on S3 data lake hosted using popular open source formats like CSV, JSON, Parquet and Avro. AWS Glue ETL jobs can reference both tables hosted on Amazon Redshift and Amazon S3 by accessing them through the common Lake Formation catalog (which the AWS Glue crawler populates by collecting data from Amazon S3 as well as Amazon Redshift). AWS Glue ETL provides step-by-step processing of partitioned data. Additionally, AWS Glue provides triggers and workflow capabilities that you can use to build a multi-step end-to-end data processing pipeline that includes job dependencies as well as running parallel steps.
You can dynamically scale EMR clusters to meet the varying resource needs of big data pipelines that can handle up to petabytes of data. These pipelines can use different groups of Amazon Elastic Compute Cloud (Amazon EC2) Spot Instances to scale in a cost-effective manner.
Spark data processing pipelines based on Amazon EMR can be used as follows:
- Spark’s built-in reader for processing data sets stored in data lakes in various open source formats
- Open source Spark-Amazon Redshift connector to directly read and write data in the Amazon Redshift data warehouse
To read schemas of complex structured datasets stored on data lakes, Spark ETLs on Amazon EMR jobs can connect to the Lake Formation catalog. This is set up with AWS Glue compatibility and AWS Identity and Access Management (IAM) policies set up to separately grant access to AWS Glue tables and underlying S3 objects.
Similar Spark jobs can use the Spark-Amazon Redshift connector to read both the data and the schema of the dataset stored in Amazon Redshift. You can use Spark and Apache Hudi to build high-performance Amazon EMR incremental data processing pipelines.
3.3. Near-real-time ETL
To enable some use cases using modern analytics, you need to perform the following actions, all in near-real time:
- Import high-frequency or streaming data in bulk
- Validate, clean, and enrich
- Prepared for consumption in Lakehouse storage
You can build easily scalable pipelines to process large volumes of data in near real time using one of the following:
- Amazon Kinesis Data Analytics for SQL/Flink
- Spark streaming on either AWS Glue or Amazon EMR
- Kinesis Data Firehose integrated with AWS Lambda
Kinesis Data Analytics, AWS Glue, and Kinesis Data Firehose let you build near-real-time data processing pipelines without creating or managing computing infrastructure. Kinesis Data Firehose and Kinesis Data Analytics pipelines scale dynamically to match source throughput, while Amazon EMR and AWS Glue-based Spark streaming jobs can be scaled in minutes by using Specifies scale parameters.
Kinesis Data Analytics for Flink/SQL based streaming pipelines typically reads records from Amazon Kinesis Data Streams (in the ingestion layer of Lakehouse Architecture), applies transformations, and writes the processed data to Kinesis Data Firehose. Spark streaming pipelines typically read records from Kinesis Data Streams (in the ingestion layer of Lakehouse Architecture), apply transformations to them, and write processed data to another Kinesis data stream, which is linked to Kinesis Data Firehose delivery stream.
The Firehose delivery stream can deliver processed data to Amazon S3 or Amazon Redshift in the Lakehouse storage layer. To build simpler near-real-time pipelines that require simple, stateless transformations, you can import data directly into Kinesis Data Firehose and convert micro-batches of incoming records using the Lambda function provided Kinesis Data Firehose invoke. Kinesis Data Firehose provides micro-batches records that have been transformed to Amazon S3 or Amazon Redshift in the Lakehouse storage layer.
With the ability to feed data to Amazon S3 as well as Amazon Redshift, Kinesis Data Firehose provides a unified Lakehouse storage interface for near-real-time ETL pipelines in the processing layer. On Amazon S3, Kinesis Data Firehose can store data in efficient Parquet or ORC files that are compressed using open source codecs such as ZIP, GZIP, and Snappy.
4. Data Consumption Layer
Our Lakehouse architecture democratizes data consumption across different persona types by providing purpose-built AWS services that enable a wide variety of analytics use cases, such as like interactive SQL queries, BI and ML. These services use a unified Lakehouse interface to access all data and metadata stored in Amazon S3, Amazon Redshift, and the Lake Formation catalog. They can use flat relational data stored in Amazon Redshift tables as well as flat or complex structured or unstructured data stored in S3 objects using open file formats such as JSON, Avro, Parquet and ORC.
4.1. Interactive SQL
To explore all data stored in Lakehouse storage using interactive SQL, business analysts and data scientists can use Amazon Redshift (with Redshift Spectrum) or Athena. You can run SQL queries that combine flat, relational, structured dimensions data stored in an Amazon Redshift cluster, with terabytes of flat or complex structured historical facts in Amazon S3, stored using open file formats like JSON, Avro, Parquet, and ORC.
When querying a dataset in Amazon S3, both Athena and Redshift Spectrum fetch the schema stored in the Lake Formation catalog and apply it on read (schema-on-read). You can run Athena or Amazon Redshift queries on their respective consoles, or you can send them to JDBC or ODBC endpoints.
Athena can run complex ANSI SQL on tens of terabytes of data stored in Amazon S3 without requiring you to load it into the database first. Athena has no servers, so there’s no infrastructure to set up or manage, and you only pay for the amount of data scanned by the queries you run. The federated query capability in Athena allows SQL queries to combine actual data stored in Amazon S3 with dimension tables stored in an Amazon Redshift cluster, without the need to migrate data in a single instance. in two directions.
You can also include data directly in the active database in the same SQL statement using Athena join queries. Athena provides faster results and lower costs by reducing the amount of data it scans by leveraging dataset partitioning information stored in the Lake Formation catalog. You can further reduce costs by caching the results of a repeated query using Athena CTAS statements.
Amazon Redshift provides powerful SQL capabilities designed for rapid online analytical processing (OLAP) of very large data sets stored in Lakehouse storage (across the entire Amazon Redshift MPP cluster as well as data lake S3). The powerful query optimizer in Amazon Redshift can take complex user queries written in PostgreSQL-like syntax and generate high-performance query plans that run on Amazon Redshift MPP clusters and clusters of nodes Redshift Spectrum (for querying data in Amazon S3) .
Amazon Redshift provides results caching capabilities to reduce query runtime for repeated runs of the same query in order of magnitude. With materialized views in Amazon Redshift, you can precompute complex joins once (and gradually refresh them) to dramatically simplify and speed up downstream queries that users need to write. Amazon Redshift provides concurrency scaling, which increases additional temporary clusters within seconds, to support a virtually unlimited number of concurrent queries. You can write your query results back to Amazon Redshift’s native tables or to external tables hosted on the S3 data lake (using Redshift Spectrum).
4.2. Machine learning
Typically, Data scientists need to explore, learn, and build features for a variety of structured and unstructured datasets in preparation for training ML models. The Lakehouse architecture interface (an interactive SQL interface using Amazon Redshift with Athena and Spark interfaces) simplifies and accelerates these data preparation steps by providing Data scientists with the following:
- A unified Lake Formation catalog to search and explore all data stored in Lakehouse storage nhớ
- Amazon Redshift SQL and Athena-based SQL interoperability to access, discover, and transform all data in Lakehouse storage
- Unified Spark-based Access to wrap and transform all data sets stored on Lakehouse storage (structured as well as unstructured) and turn them into feature sets
Data scientists then develop, train, and deploy ML models by connecting Amazon SageMaker to the Lakehouse storage layer and accessing the training feature sets.
SageMaker is a fully managed service that provides components for building, training, and deploying ML models using an interactive development environment (IDE) called SageMaker Studio. In Studio, you can upload data, create new notebooks, train and tune models, move back and forth between steps for test tuning, compare results, and deploy the model to production. all in one place with a unified visual interface.
SageMaker also offers Jupyter notebooks that you can cycle through with a few clicks. SageMaker notebooks offer flexible computing resources, git integration, easy sharing, pre-configured ML algorithms, dozens of pre-built ML examples, and AWS Marketplace integration that allows for easy deployment of hundreds of algorithms pre-trained math. SageMaker notebook comes preconfigured with all major deep learning frameworks including TensorFlow, PyTorch, Apache MXNet, Chainer, Keras, Gluon, Horovod, Scikit-learning and Deep Graph Library.
ML models are trained on managed compute instances by SageMaker, including the highly cost-effective EC2 Spot Instances. You can organize a variety of training tasks using SageMaker Experiments. You can build training jobs using SageMaker’s built-in algorithms, your own custom algorithms, or hundreds of algorithms you can deploy from the AWS Marketplace. SageMaker Debugger provides full visibility into model training jobs. SageMaker also provides automatic hyperparameter tuning for ML training jobs.
You can deploy SageMaker trained models to production with a few clicks and easily scale them across a group of fully managed EC2 instances. You can choose from a variety of EC2 instances and attach GPU-powered inference acceleration. After you deploy the models, SageMaker can monitor the model’s key metrics for inference accuracy and detect any conceptual deviations.
4.3. Business intelligence
Amazon QuickSight provides serverless capabilities to easily create and publish rich, interactive BI dashboards. Business analysts can use the Athena or Amazon Redshift interactive SQL interfaces to power the QuickSight dashboard with Lakehouse in-memory data. In addition, you can create data sources by connecting QuickSight directly to operational databases such as MS SQL, Postgres, and SaaS applications such as Salesforce, Square, and ServiceNow. For blazing fast dashboard performance, QuickSight offers an in-memory caching and compute engine called SPICE. SPICE automatically replicates data for high availability and enables thousands of concurrent users to perform fast, interactive analysis while protecting your underlying data infrastructure.
QuickSight enriches dashboards and visualizations with unique, auto-generated ML insights, such as forecasting, anomaly detection, and narrative highlights. QuickSight integrates natively with SageMaker to allow additional custom ML model-driven insights to be added to your BI dashboard. You can access the QuickSight dashboard from any device using the QuickSight app, or embed the dashboard in web apps, portals, and websites. QuickSight automatically scales to tens of thousands of users and provides a cost-effective pay-per-session pricing model.
Let’s take a look at the overall reference model from the AWS compiled by Viet-AWS
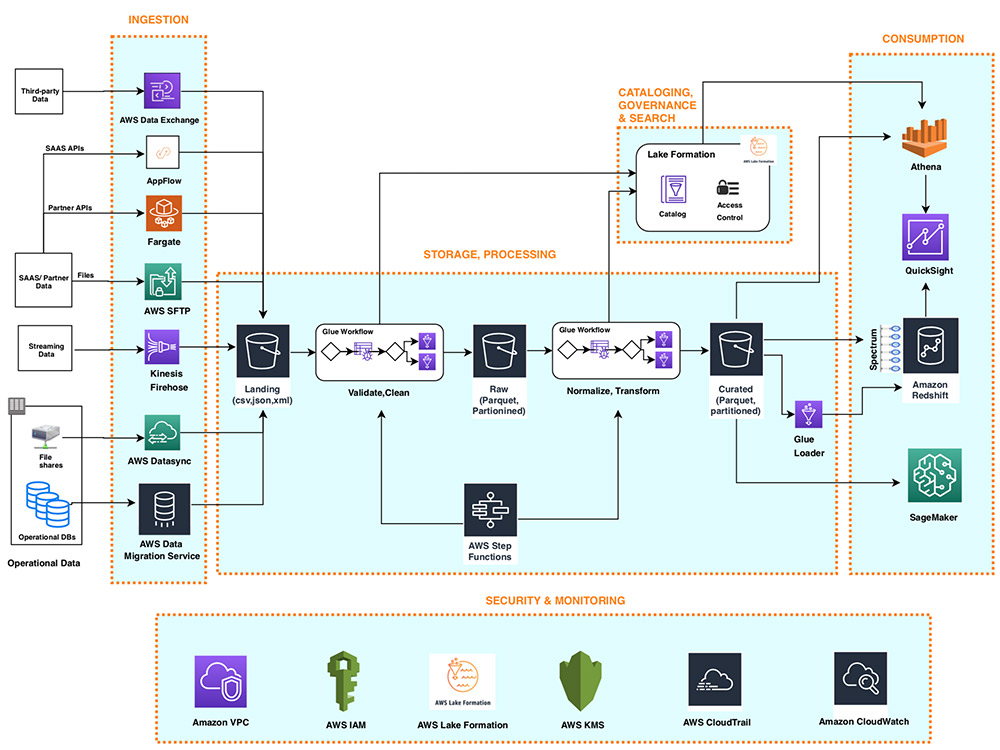
Summary of articles on Data Lakehouse with AWS
The Lakehouse Architecture, built on top of a portfolio of purpose-built services, will help you quickly get insights from all data for all users and will allow you to build for future so that new analytical methods and technologies can be easily added as they become available.
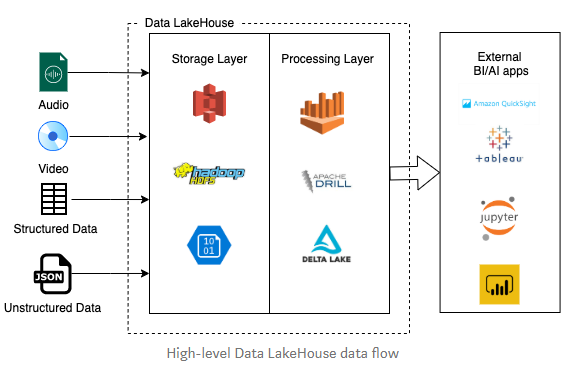
In this post, we described some purpose-built AWS services that you can use to create the five layers of the Lakehouse Architecture. We introduced many options to demonstrate the flexibility and rich capabilities offered by the right AWS service for the right job.