How to build Lakehouse Architecture on AWS (Part 2)
Following part 1, the following section will introduce a reference architecture that uses AWS services to create each layer described in the Lakehouse architecture.
See also part 1 on the How to build Lakehouse Architecture on AWS (Part 1) – Viet-AWS (awsviet.vn)
In this approach, AWS services take care of the following heavy lifting:
- Provision and manage scalable, flexible, secure, and cost-effective infrastructure components
- Ensure infrastructure components integrate naturally with each other
This approach allows you to focus more of your time on the following:
- Quickly build analytics and data pipelines
- Dramatically accelerate the integration of new data and drive insights from your data
- Support multiple user personalities
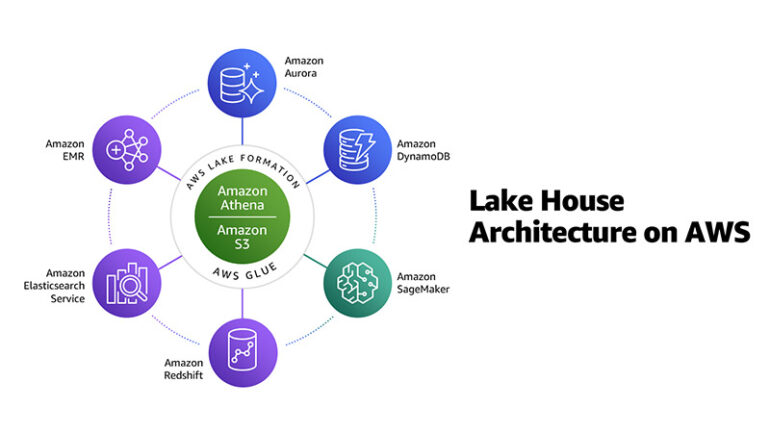
Lakehouse Reference Architecture on AWS
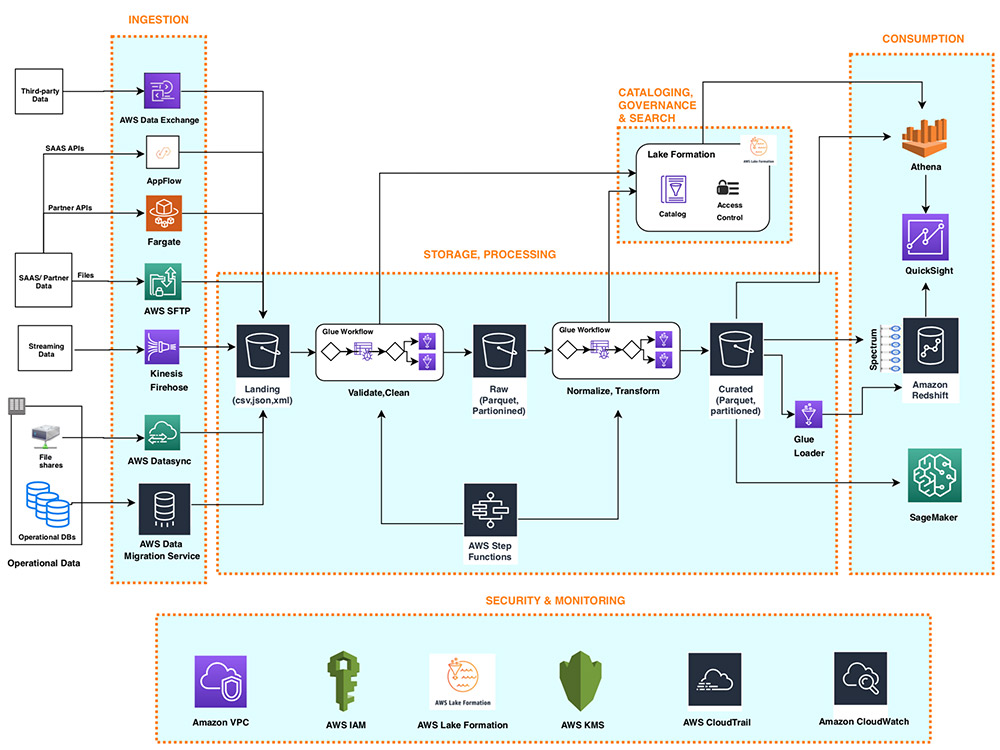
The following diagram illustrates the Lakehouse reference architecture on AWS:
In the following sections, Viet-AWS provides more information about each layer.
1. Data Ingestion Layer
The data ingestion layer in our Lakehouse reference architecture includes a set of purpose-built AWS services to enable the ingestion of data from a variety of sources into the Lakehouse storage layer. Most ingest services can feed data directly to both the data lake and data warehouse storage. Purpose-built AWS services are tailored to the unique connectivity, data formats, data structures, and data rates requirements of the following sources:
- Operational database
- SaaS Application
- File sharing
- Streaming data
1.1. Operational database sources (OLTP, ERP, CRM)
The AWS Data Migration Service (AWS DMS) component in the ingestion layer can connect to several active RDBMS and NoSQL databases and import their data into an Amazon Simple Storage Service (Amazon S3) bucket in the data lake or directly to staging tables in the Amazon Redshift data warehouse. With AWS DMS, you can do a one-time import of source data and then replicate the changes that are happening in the source database.
1.2. SaaS applications
The Ingestion layer uses Amazon AppFlow to easily import SaaS application data into your data lake. With a few clicks, you can set up a serverless ingest flow in Amazon AppFlow.
Your flows can connect to SaaS applications like Salesforce, Marketo, and Google Analytics, ingest and deliver that data to the Lakehouse storage layer, to the S3 bucket in the data lake, or directly to the staging tables in the data warehouse. Amazon Redshift. You can schedule Amazon AppFlow data ingestion flows or trigger them with SaaS application events. Imported data can be validated, filtered, mapped, and masked prior to delivery to Lakehouse storage.
1.3. File shares
Many applications store structured and unstructured data in files stored on network hard drives (NAS). AWS DataSync can import hundreds of terabytes and millions of files from NFS and SMB-enabled NAS devices into the data lake destination.
DataSync automates scripting of replication jobs, schedules and monitors transfers, validates data integrity, and optimizes network usage. DataSync can do a file transfer once and then track and sync the changed files into Lakehouse. DataSync is fully managed and can be set up in minutes.
1.4. Streaming data
The Ingestion layer uses Amazon Kinesis Data Firehose to receive streaming data from internal or external sources and deliver it to the Lakehouse storage layer. With a few clicks, you can configure the Kinesis Data Firehose API endpoint where sources can send streaming data such as clickstreams, application logs, infrastructure and monitoring metrics, and data. IoT data such as telemetry and sensor reading. Kinesis Data Firehose performs the following actions:
- Buffer incoming streams
- Sync, compress, convert, partition and encrypt data
- Feed data as S3 objects into the data lake or as rows into staging tables in the Amazon Redshift data warehouse
Kinesis Data Firehose is serverless, requires no administration, and you only pay for the volume of data you transmit and process through the service. Kinesis Data Firehose automatically scales to adjust to the volume and throughput of incoming data. To build a real-time streaming analytics pipeline, the ingestion layer provides Amazon Kinesis Data Streams.
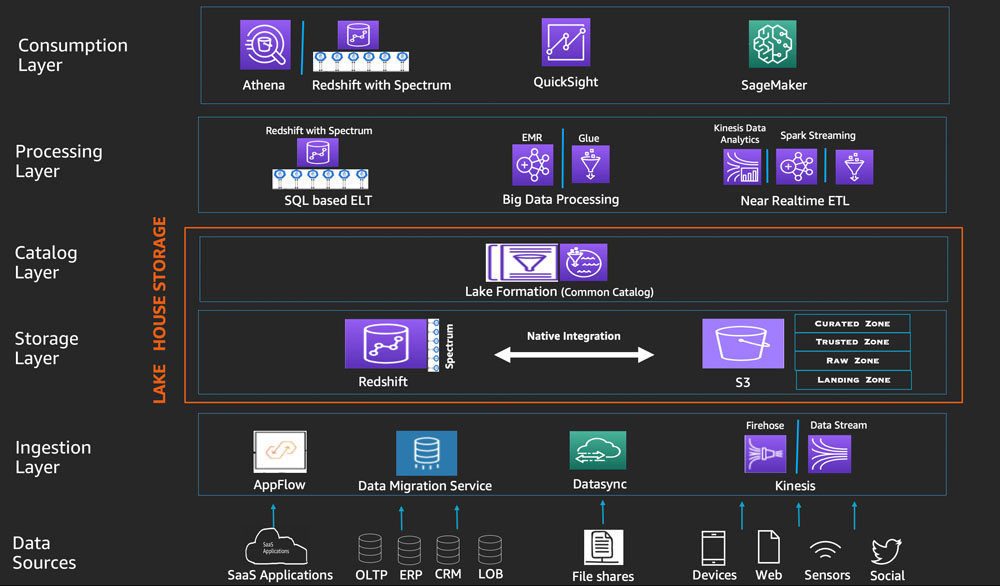
2. Lakehouse Storage Layer
Amazon Redshift and Amazon S3 provide a unified, natively integrated storage layer of the Lakehouse reference architecture. Typically, Amazon Redshift stores reliable, consistent, and highly managed data structured into standard dimensional schemas, while Amazon S3 provides exabyte-scale data lake storage for structured data structured, semi-structured and unstructured.
With support for semi-structured data in Amazon Redshift, you can also import and store semi-structured data in your Amazon Redshift data warehouse. Amazon S3 offers industry-leading scalability, data availability, security, and performance. Organizations typically store data in Amazon S3 using open file formats. Open file formats allow the same Amazon S3 data to be analyzed using multiple processing and consuming layer components.
The global catalog class stores structured or semi-structured data set schemas in Amazon S3. Components that use S3 datasets typically apply this schema to the dataset as they read it (aka schema-on-read).
Amazon Redshift Spectrum is one of the hubs of the natively integrated Lakehouse storage layer. Redshift Spectrum enables Amazon Redshift to present a unified SQL interface that can accept and process SQL statements where the same query can reference and combine data sets stored in the data lake as well as stored in the data warehouse.
Amazon Redshift can query petabytes of data stored in Amazon S3 using a layer of up to thousands of temporary Redshift Spectrum nodes and applying complex Amazon Redshift query optimizations. Redshift Spectrum can query data partitioned in data lake S3. It can read data compressed with open source codecs and stored in open source row or column formats including JSON, CSV, Avro, Parquet, ORC, and Apache Hudi.
When Redshift Spectrum reads data sets stored in Amazon S3, it applies the corresponding schema from the common AWS Lake Formation catalog to the data (schema-on-read). With Redshift Spectrum, you can build Amazon Redshift native pipelines that perform the following actions:
- Store large volumes of historical data in a data lake and import several months of hot data into a data warehouse using Redshift Spectrum
- Create a granularly augmented dataset by processing both hot data in attached storage and historical data in a data lake, all without moving data in either direction
- Insert detailed data set rows into a table stored on attached storage or directly into an external table stored in the data lake
- Easily offload large volumes of historical data from the data warehouse into cheaper data lake storage and still easily query it as part of Amazon Redshift queries
Highly structured data in Amazon Redshift typically supports fast, reliable BI dashboards and interactive queries, while structured, unstructured, and semi-structured data in Amazon S3 often drives ML use cases, data science, and big data processing.
AWS DMS and Amazon AppFlow in the ingestion layer can deliver data from structured sources directly to the S3 data lake or Amazon Redshift data warehouse to meet use case requirements. In the case of importing data files, DataSync brings the data into Amazon S3. Processing layer components can access data in the unified Lakehouse storage layer through a single unified interface such as Amazon Redshift SQL, which can combine data stored in an Amazon Redshift cluster with data in Amazon S3 using Redshift Spectrum.
In S3 Data Lake, both structured and unstructured data are stored as S3 objects. The S3 objects in the data lake are organized into groups or prefixes that represent the landing, raw, trusted, and curated regions. For pipelines that store data in the S3 data lake, data is imported from the source into the destination pool as it is.
The processing layer then validates the landing zone data and stores it in a raw or prefix zone group for permanent storage. The processing layer applies schema, partitioning, and other transformations to the raw data to bring it to the proper state and store it in the trusted region. As a final step, the processing layer sorts a trusted region dataset by modeling it, combines it with other datasets, and stores it in a curated layer. Typically, data sets from the curated layer are partially or fully imported into an Amazon Redshift data store for use cases that require very low latency access or need to run complex SQL queries.
The dataset in each region is typically partitioned along a key that matches a specific consumption pattern for the respective region (raw, trusted, or sorted). S3 objects correspond to a compressed dataset, using open source codecs such as GZIP, BZIP, and Snappy, to reduce storage costs and read time for components in the processing and consuming layer. Data sets are often stored in open source columnar formats such as Parquet and ORC to further reduce the amount of data read when the components of the processing and consuming layer query only a subset of the columns. Amazon S3 offers a variety of storage layers designed for different use cases. Amazon S3’s intelligent hierarchical storage layer is designed to optimize costs by automatically migrating data to the most cost-effective access level without impacting performance or operational costs.
Amazon Redshift provides a petabyte-scale data warehouse of highly structured data that is often modeled into dimensional or denormalized schemas. On Amazon Redshift, data is stored in a columnar format, highly compressed, and stored in a distributed fashion across a cluster of high-performance nodes. Each node provides up to 64 TB of highly efficient managed storage. Amazon Redshift enables high data quality and consistency by enforcing schema transactions, ACID, and workload isolation. Organizations typically store highly compliant, harmonized, trusted, and managed dataset structured data on Amazon Redshift to serve use cases that require very high throughput, very low latency and at the same time high. You can also use refreshed step-by-step materialized views in Amazon Redshift to dramatically increase the performance and throughput of complex queries generated by the BI console.
When you build a Lakehouse by importing data from a variety of sources, you can often start storing hundreds to thousands of datasets on your data lake and data warehouse. A central data catalog to provide metadata for all datasets in Lakehouse storage (data warehouse as well as data lake) in a single and easily searchable place is important for self-discovery. data in the Lakehouse. Additionally, separating metadata from data stored in the data lake into a central schema enables schema-on-read for the processing and consumption layer components as well as the Redshift Spectrum.
In the Lakehouse reference architecture, Lake Formation provides a central catalog for storing metadata for all data sets stored in Lakehouse (whether stored in Amazon S3 or Amazon Redshift). Organizations store both technical metadata (such as versioned table schemas, partition information, physical data location, and update timestamps) and business attributes (such as data owner, data managers, column business definitions and column sensitivity) of all their datasets in Lake Formation.
Many datasets stored in a data lake often have schemas that are constantly growing and data partitioning, while dataset schemas stored in a data warehouse grow in a managed manner. AWS Glue Data Collector tracks evolving schemas and newly added data partitions stored in datasets stored in data lake and datasets stored in data warehouse and adds new instances of the respective schemas in the Lake Formation catalog. Additionally, Lake Formation provides APIs to enable registration and metadata management using custom scripts and third-party products.
Lake Formation provides data lake administrators with a hub to set granular table and column level permissions for databases and tables stored in the data lake. After you set up Lake Formation permissions, users and groups can only access authorized tables and columns using a variety of processing and consumption layer services such as AWS Glue, Amazon EMR, Amazon Athena, and Redshift Spectrum.
To be continued…