Introducing AWS Big Data solutions
Want to build an end-to-end data pipeline with AWS services?
Congratulations! In this post, Viet-AWS will introduce AWS’ Big Data portfolio.
Before we dive into the AWS service set for Big Data, let’s first determine what Big Data is.
What is big data?
Theo Amazon Web Services (AWS):
Big data can be described as data management challenges – due to the increasing volume, speed of formation and diversity of data – that cannot be solved by traditional databases.
To put it more simply:
Data sets are considered Big Data when it is too large or complex to be stored or analyzed by traditional data systems.
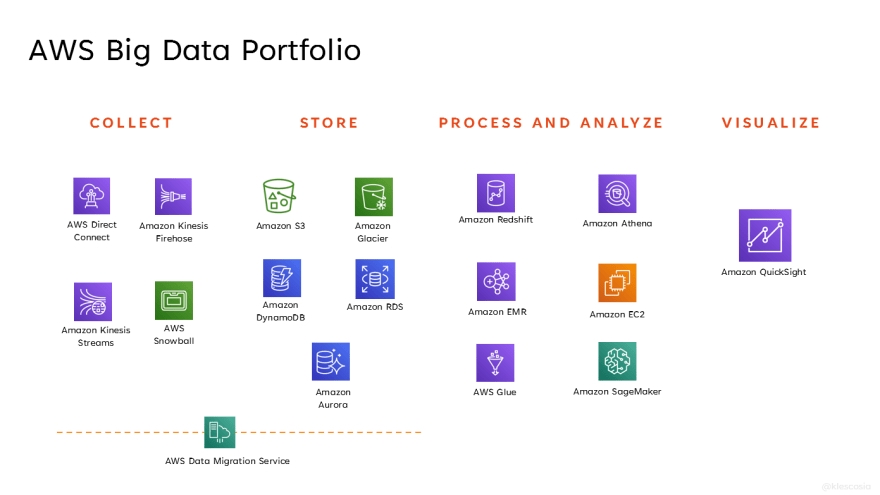
When determining what Big Data is, we will continue with aws services used to help solve The Big Data challenges.
Stage 1: Collect
Raw data collection is always a challenge for many organizations, especially for developers because businesses always have different complex source systems scattered throughout the company such as ERP systems, CRM systems, transaction databases, etc.
Businesses must also think about how they will integrate data between these systems to create a unified view for company data.
AWS makes it easier for businesses to take these steps, allowing developers to enter data (structured and unstructured) in real time in bulk.
Collection support services
AWS Direct Connect
AWS Direct Connect is a network service that provides an alternative to using the internet to connect to AWS.
Using AWS Direct Connect, data previously transmitted over the internet will be distributed via a private network connection between user and AWS facilities.
This is useful if the user wants to have consistent network performance or if there is a high workload of bandwidth.
Read more in the previous article of Viet-AWS: What is AWS Direct Connect? – Viet-AWS (awsviet.vn)
Amazon Kinesis
Easily collect, process, and analyze video streams and data in real time.
Amazon Kinesis allows data processing and analysis when data arrives and responds immediately instead of having to wait until all data is collected before processing can begin.
Amazon Kinesis is fully managed and runs enterprise streaming apps without requiring management of any infrastructure.
Kinesis has four functions:
- Kinesis Video Streams: Recording, processing and storing video streams
- Kinesis Data Streams: Capture, process and store data streams
- Kinesis Data Firehose: Download the data flow to the AWS data warehouse
- Kinesis Data Analytics: Data flow analysis with SQL or Apache Flink
Amazon Kinesis Video Streams
Kinesis Video Streams makes it easy to stream video securely from connected devices to AWS for analysis, machine learning (ML) and other processing processes.
Amazon Kinesis Data Streams
Kinesis Data Streams is an expandable and durable real-time data transfer service that can continuously collect gigabytes (GB) of data per second from hundreds of thousands of different sources.
Amazon Kinesis Data Firehose
Kinesis Data Analytics is the easiest way to process data streams in real time with SQL or Apache Flink without having to learn new programming languages or frameworks.
Amazon Kinesis Data Analytics
Kinesis Data Analytics is the easiest way to process data streams in real time with SQL or Apache Flink without having to learn new programming languages or frameworks.
AWS Snowball
A pretty fun way to move your data from on-premises infrastructure to AWS Cloud is AWS Snowball. It provides secure and secure devices, so you can bring AWS storage and computing capabilities into marginal environments, while simultaneously transmitting data into and out of AWS.
Amazon S3
Amazon S3 Glacier is an ultra-low-cost storage service that provides safe, durable and flexible storage for data backup and storage.
This perfectly meets the needs of businesses or organizations that need to store their data for years and even decades!
Stage 2: Storage
We are actually big fans of the Amazon S3, due to its scalability and easy use. If you’re not using the Amazon S3 for your datalakes, you’re probably missing out on a lot of things.
Obviously, there are a lot of factors that need to be considered when building a Big Data project. Any Big Data platform needs a secure, flexible, and durable repository to store data before or even after handling tasks, AWS provides services depending on the specific requirements of the customer.
Storage support services
Amazon DynamoDB
Amazon DynamoDB is a document database that delivers performance of up to one millisecond at any scale.
It’s one of those fully managed AWS Services, which means you don’t have to worry about setting up infrastructure and updating software, just using the service.
Read more: https://aws.amazon.com/dynamodb/
Amazon RDS
Amazon RDS is a managed service that makes it easy to set up, operate, and scale a relationship database in the cloud.
Amazon RDS supports the Amazon Aurora, MySQL, MariaDB, Oracle, SQL Server, and PostgreSQL database tools and is often the service used when customers migrate databases from on-premises to AWS.
Amazon Aurora
Amazon Aurora is a relational database tool that combines the speed and reliability of a premium commercial database with the simplicity and cost-effectiveness of an open source database.
Stage 3: Processing and analysis
This is the step by which data is transferred from its raw state into a consumerable format – often by organizing, synthesizing, joining, and even performing more advanced functions and algorithms.
The resulting data sets are then stored for further processing or available for consumption through data visualization tools and business intelligence.
Services to support processing and analysis
Amazon Redshift
Amazon Redshift is the most widely used cloud data warehouse.
It helps analyze all your data quickly, simply and cost-effectively using standard SQL and your existing Business Intelligence (BI) tools.
It allows you to run complex analytical queries from terabytes (TB) to petabytes (PB, 1 PB of structured and semi-structured data), using complex query optimization, high-performance memory-based storage, and mass parallel query execution.
Amazon Athena
Amazon Athena is an interactive query service that makes it easy to analyze data in the Amazon S3 using standard SQL.
The Amazon Athena service doesn’t have servers, so there’s no infrastructure to manage and you only pay for the queries you run.
We used Athena a lot in our deployment and I have to say that they really helped us in terms of Data Discovery and Data Authentication.
AWS Glue
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analysis, machine learning, and application development.
AWS Glue has grown significantly from the initial release of 0.9 to AWS Glue 2.0. Along with that are improvements that help bring all pipelines together.
Amazon EMR
Amazon EMR is a web service that allows businesses, researchers, data analysts, and developers to process large amounts of data easily and cost-effectively.
It uses a hosted Hadoop framework that runs on the web-scale infrastructure of Amazon Elastic Compute Cloud (Amazon EC2) and Amazon Simple Storage Service (Amazon S3).
In contrast to Glue, without a server means you don’t need to provide your own server, EMR gives you more flexibility in terms of workload depending on how “large” your data processing workload is.
Amazon EC2
Amazon Elastic Compute Cloud (Amazon EC2) is a web service that provides resizeable computing capabilities in the cloud. Basically, your virtual machine in the cloud has a lot of use cases, true to its name “Elastic”.
Amazon Sagemaker
Amazon SageMaker is a fully managed service that gives every developer and data scientist the ability to build, train, and deploy machine learning (ML) models quickly.
SageMaker removes the heavy lifting from every step of the machine learning process to make it easier to develop high-quality models.
AWS re: Invent 2020 has also introduced us to a lot of significant improvements to Amazon Sagemaker such as Data Wrangler, Clarify, SageMaker pipe, etc.
Stage 4: Visualization
Big data is all about getting high value, useful insights from the content of your data.
Ideally, data is provided to stakeholders through self-service business intelligence tools and flexible data visualization tools that enable quick and easy data set discovery.
Depending on the type of analysis, the end user can also use the resulting data in the form of statistical “prediction” – in the case of predictive analysis – or proposed action – in the case of descriptive analysis.
Services that support visualization
Amazon QuickSight
Amazon QuickSight is a cloud-enabled Business Analytics service that is fast, easy to use, making it easy for all employees in the organization to visualize, perform special analytics, and quickly receive business insights from their data, at any time, On any device.
QuickSight is easy to use and has also made some major improvements since its public release. Although relatively new to other large BI tools, Amazon QuickSight has a lot of potential, especially when it is a cost-saving BI solution.
References:
https://aws.amazon.com/directconnect/
https://aws.amazon.com/kinesis/
https://aws.amazon.com/snowball/
https://aws.amazon.com/glacier/
https://aws.amazon.com/dynamodb/
https://aws.amazon.com/redshift/
https://aws.amazon.com/athena/